


There were two things which pushed me to write down this code:-
1. Diapers are expensive and saving a dollar or two on it every month is cool.
2. If you are not using python to automate certain stuff, you are not doing it right.
So, here is how I used web scrapping to find cheap deals on diapers:-
Amazon has certain Warehouse deals, which at least in the case of diapers consists of the products, which are returned by the buyers and have defective original packaging. But, the product inside is mostly new and unused. So, finding such deals can help you save few dollars on certain stuff. So, let’s go down to the coding part :
We will be using requests and BeautifulSoup. So, let’s import them and since amazon.com doesn’t like python scrolling through its website, let’s add some headers.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36"
}
Now, we will have to find the target URL, you can easily find it by browsing the website, selecting the warehouse deals from the drop-down menu, entering the keywords and hitting the search button. Let me make it easy for you. Just enter the following codes:-
AMAZON = 'https:/www.amazon.com'
BASE_URL = 'https://www.amazon.com/s/search-alias%3Dwarehouse-deals&field-keywords='
SEARCH_WORDS = 'huggies+little+movers+Size 4'
url = BASE_URL + SEARCH_WORDS
If you will search on the website manually, you will get the following sort of screen:-
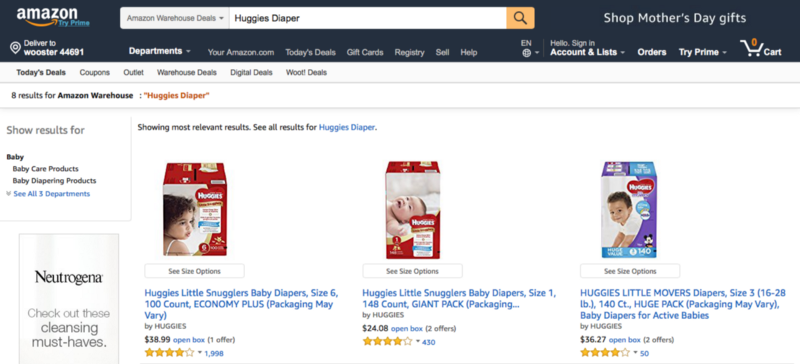
You need to focus on the line which says 8 results for Amazon Warehouse: “Huggies Diaper”. Now, we can encounter following four cases, when we search for an item in Warehouse deals:-
- There is no deal present.
- There are limited numbers of deals present and all of them are on one page. (e.g. 8 results for Amazon Warehouse: “Huggies Diaper”)
- There are limited numbers of deals present but are spread across more than one page. (e.g. 1–24 of 70 results for Amazon Warehouse : “huggies”)
- There are more than 1000 deals present ( e.g. 1–24 of over 4,000 results for Amazon Warehouse : “iphone”)
I will be dealing with above as under:-
In the case of no deals present, I will be exiting the function. (We can log such cases)
In the second case, we will be creating a dictionary of the data using the function scrap_data(). We will be checking it out in details soon.
In the third and four cases, we will have to scrape through multiple pages and to keep it simple we will be going through a maximum of 96 results i.e. 4 pages.
So let’s create a soup using BeautifulSoup and requests, since we will be creating soups for multiple urls in certain cases, it is better to create a different function for that:-
def create_soup(url):
req = requests.get(url, headers=HEADERS)
soup = BeautifulSoup(req.text, 'html.parser')
return soup
If we inspect the element, we will find that the said line of text has span id = “s-result-count”. Now, we will grab the text using the following code:-
result = soup.find("span", id="s-result-count").text
We will use regex to match the third and fourth scenario and will just search the first 96 results ( or four pages) in case of the fourth scenario. The code for the same would be as under:-
import re
def parse_result(result):
''' This will take care of 4 cases of results
Case 1 When no result is available.
Case 2 When all the results available are shown on first page only i.e. 24 results.
Case 3 When there are more than 24 results and there are more than one page but the number of result is certain.
Case 4 When there are over 500, 1000 or more results.
'''
matchRegex = re.compile(r'''(
(1-\d+)\s
(of)\s
(over\s)?
(\d,\d+|\d+)\s
)''', re.VERBOSE)
matchGroup = matchRegex.findall(result)
# Case 1 simply exits the function
# TODO Log such cases
if "Amazon Warehouse" not in result:
exit()
else:
# Case2
if not matchGroup:
resultCount = int(result.split()[0])
# Case4
elif matchGroup[0][3] == "over ":
resultCount = 96
# Case3
else:
resultCount = min([(int(matchGroup[0][4])), 96])
return resultCount
Let’s crunch few numbers and get the resultCount and the number of pages we need to navigate:-
def crunch_numbers():
soup = create_soup(url)
result = soup.find("span", id="s-result-count").text
resultCount = parse_result(result)
navPages = min([resultCount // 24 + 1, 4])
return resultCount, navPages
So, finally we have a target number in the form of resultCount and we will be extracting the data for that number. On closely inspecting the element of the webpage, you will find that all the results are inside the li tag with an id= “result_0” onwards (Yes, they are zero-indexed).
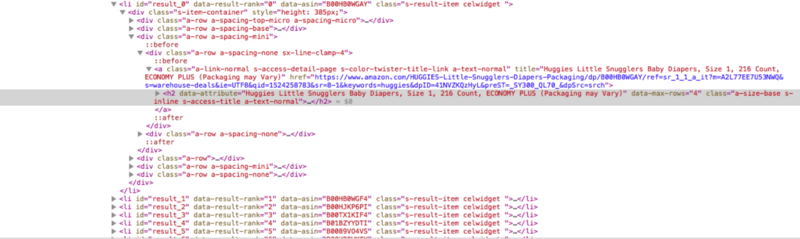
The name of the item, link and price are in h2, a and span tag inside the li tag. However, though the results upto number 96 will be with id “result_96”, but they will be distributed across 4 pages. So, we need to get the url of the preceding pages also. So, the link to the second page of results is in a span with a class “pagenLink” and it has two references to the page number “sr_pg_2” and “page=2”. So, if we will grab this, we can easily get the next two urls by replacing 2 with 3 and 4 for next pages:-

Depending upon the number of navPages, we will be creating a dictionary to replace the digit “2” with the desired digit as under:-
dict_list = [{
"sr_pg_2": "sr_pg_" + str(i),
"page=2": "page=" + str(i)
} for i in range(2, navPages + 1)]
We, will be grabbing the second url using the following code:-
nextUrl = soup.find("span", class_="pagnLink").find("a")["href"]
And, replacing the digit using the following function:-
def get_url(text, dict):
for key, value in dict.items():
url = AMAZON + text.replace(key, value)
return url
Finally, we will be extracting the Name, Url and the price of the desired product. In case of more than one result pages, we will be using if elif statements to create new soups for the next urls grabbed above. Lastly, we will append the data to a dictionary for further processing. The code will be as under:-
def scrap_data():
resultCount, navPages = crunch_numbers()
soup = create_soup(url)
try:
nextUrl = soup.find("span", class_="pagnLink").find("a")["href"]
renameDicts = [{
"sr_pg_2": "sr_pg_" + str(i),
"page=2": "page=" + str(i)
} for i in range(2, navPages + 1)]
urlList = [get_url(nextUrl, dict) for dict in renameDicts]
except AttributeError:
pass
productName = []
productLink = []
productPrice = []
for i in range(resultCount):
if i > 23 and i <= 47:
soup = create_soup(urlList[0])
elif i > 47 and i <= 71:
soup = create_soup(urlList[1])
elif i > 71:
soup = create_soup(urlList[2])
id = "result_{}".format(i)
try:
name = soup.find("li", id=id).find("h2").text
link = soup.find("li", id="result_{}".format(i)).find("a")["href"]
price = soup.find(
"li", id="result_{}".format(i)).find("span", {
'class': 'a-size-base'
}).text
except AttributeError:
name = "Not Available"
link = "Not Available"
price = "Not Available"
productName.append(name)
productLink.append(link)
productPrice.append(price)
finalDict = {
name: [link, price]
for name, link, price in zip(productName, productLink, productPrice)
}
return finalDict
In order to automate the process, we will want our programme to send us the list of the products available at the particular time. For this, we will be creating an empty “email_message.txt” file. We will further filter the finalDict generated by scrap_data.py and create a custom email message using the following code:
def create_email_message():
finalDict = scrap_data()
notifyDict = {}
with open("email_message.txt", 'w') as f:
f.write("Dear User,\n\nFollowing deals are available now:\n\n")
for key, value in finalDict.items():
# Here we will search for certain keywords to refine our results
if "Size 4" in key:
notifyDict[key] = value
for key, value in notifyDict.items():
f.write("Product Name: " + key + "\n")
f.write("Link: " + value[0] + "\n")
f.write("Price: " + value[1] + "\n\n")
f.write("Yours Truly,\nPython Automation")
return notifyDict
```
So, now we will be notifying the user via email for that we will be using .env to save the user credentials and even the emails (though you can use the .txt file to save the emails also). You can read more about using dotenv from the link below:-
https://github.com/uditvashisht/til/blob/master/python/save-login-credential-in-env-files.md
Create an empty .env file and save the credentials:-
```
#You can enter as many emails as you want, separated by a whitespace
emails = 'user1@domain.com user2@domain.com'
MY_EMAIL_ADDRESS = "youremail@domain.com"
MY_PASSWORD = "yourpassword"
Then you will have to do following imports in your programme and the load the env as under:
import os
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv())
Further we will be using smtplib to send email. I have copied most of the code for this portion from this post by Arjun Krishna Babu:-
def notify_user():
load_dotenv(find_dotenv())
notifyDict = create_email_message()
emails = os.getenv("emails").split()
if notifyDict != {}:
s = smtplib.SMTP(host="smtp.gmail.com", port=587)
s.starttls()
s.login(os.getenv("MY_EMAIL_ADDRESS"), os.getenv("MY_PASSWORD"))
for email in emails:
msg = MIMEMultipart()
message = open("email_message.txt", "r").read()
msg['From'] = os.getenv("MY_EMAIL_ADDRESS")
msg['To'] = email
msg['Subject'] = "Hurry Up: Deals on Size-4 available."
msg.attach(MIMEText(message, 'plain'))
s.send_message(msg)
del msg
s.quit()
And finally:-
if __name__ == '__main__':
notify_user()
Now, you can schedule this script to run on your own computer or some cloud server to notify you periodically.
The complete code is available here